

Athena Cost Optimization:
Amazon Athena is a powerful query service that allows you to run SQL queries directly on data stored in S3 without having to set up or manage any infrastructure. While Athena’s pay-as-you-go model can save you time and money, inefficient queries can lead to unexpectedly high costs. In this guide, we’ll explore some of the best practices for Amazon Athena cost optimization, helping you reduce AWS query costs without sacrificing performance.
For businesses looking for expert advice, TruCost.Cloud provides specialized AWS FinOps solutions, ensuring you get the most out of your cloud investment. Learn more about how we can help you optimize your cloud spend.
Why Athena Queries Can Get Expensive
Amazon Athena charges you based on the amount of data scanned by your queries. While this sounds simple, even moderately sized datasets can result in high costs if you’re not careful. In fact, query performance and cost are directly linked to how much data is processed, making it essential to structure your data and queries efficiently.
The good news is that you can use several techniques to minimize query costs and improve performance. Let’s dive into the best practices to help you save on both costs and time.
AWS Athena Cost Optimization Best practices:
1. Use Compressed and Columnar Data Formats
One of the easiest and most effective ways to reduce data scanning costs is by using compressed, columnar data formats such as Apache Parquet or ORC (Optimized Row Columnar). These formats store data in columns rather than rows, allowing Athena to scan only the columns required by your query, reducing the amount of data scanned.
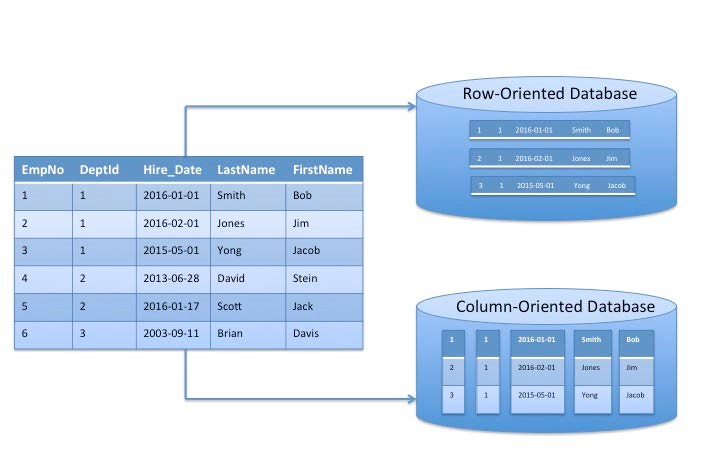
For example, if you have a dataset with 10 columns but your query only needs data from 2 of them, it will only scan the relevant columns if the data is stored in Parquet or ORC. This can reduce costs by up to 90% compared to using row-based formats like CSV or JSON.
Learn more about Athena’s pricing model here.
2. Partition Your Data: Focus on What You Need
Partitioning your data is another effective way to reduce costs. Partitioning breaks your dataset into smaller, logical units based on values in one or more columns, such as date, location, or department. By partitioning, you can instruct Athena to only scan the relevant data sections rather than the entire dataset.
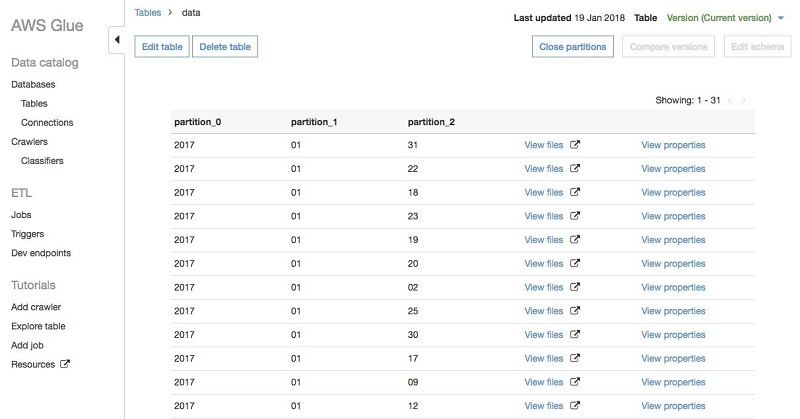
For example, if you have clickstream data, you can partition by year or month. This way, when running a query for recent months, it only scans the relevant partitions, drastically reducing data scan costs. However, make sure to keep partitions up to date with any new data and design the partitioning strategy based on your typical query patterns.
Read more about partitioning strategies here.
3. Upgrade to Athena Engine Version 3 for Enhanced Performance
Upgrading to Engine Version 3 unlocks several new features that further improve query performance, scalability, and cost efficiency. This version introduces performance optimizations, improved query execution times, and new features to reduce costs when querying large datasets.
Some of the key enhancements include:
- Dynamic memory allocation to optimize memory usage during query execution.
- Query optimizations that speed up workloads, particularly for complex queries.
- Improved cost efficiency for JOIN operations and complex analytics
tasks.
Moreover, Athena Engine Version 3 continues to support workgroup-level cost control features, which allow you to set query budgets, track costs by teams or use cases, and monitor usage in real-time. These features make it easier for organizations to maintain control over their query costs.
For businesses handling a high volume of complex queries, upgrading to Athena Engine Version 3 is essential for maximizing both query performance and cost savings.
Learn more about Athena Engine Version 3 here.
4. Write More Efficient Queries to Reduce Data Scans
Writing efficient SQL queries is an often overlooked yet highly impactful way to reduce the amount of data scanned in Athena. Avoid using “SELECT *” in your queries, as this instructs Athena to scan all columns in the dataset, even those you may not need.
Instead, explicitly name only the columns you need. For instance, if you’re analyzing specific columns like customer ID or order date, write your query to fetch only those columns. Additionally, make use of LIMIT clauses when testing queries to reduce the number of rows processed.
This simple optimization can significantly reduce Athena query costs, especially when dealing with large datasets.
5. Use AWS Glue for Data Cataloging and Schema Management
AWS Glue is an essential service for managing and optimizing data schemas in Amazon Athena. Its Data Catalog feature automatically detects, classifies, and catalogs your data, streamlining the query process and significantly improving efficiency.
One of the key advantages of using AWS Glue is its ability to centralize and manage metadata for your datasets. By creating an organized data catalog, Glue allows Athena to interact with well-structured, defined datasets, ensuring your queries are optimized for performance. Glue automates the detection of new datasets and changes to existing ones, which means your data remains up-to-date without requiring manual schema updates. This automation reduces the overhead involved in manually managing your data’s structure, freeing up your time to focus on more strategic tasks.
AWS Glue’s schema management capabilities further enhance Athena’s performance by allowing you to enforce data consistency and integrity. By ensuring that your datasets adhere to the appropriate schemas, Glue minimizes errors that can result from poorly structured or unorganized data. The service also handles schema evolution, so any changes to your data structure are automatically reflected in the Data Catalog. This helps you avoid query failures or mismatches when working with dynamic datasets.
Additionally, AWS Glue integrates seamlessly with other AWS services like S3 and Redshift, ensuring that no matter where your data resides, it is always cataloged and accessible. Glue’s ability to transform and prepare your data for analysis means that you can run more complex, efficient queries in Athena with minimal processing overhead. The combination of AWS Glue’s automated data cataloging and schema management can lead to faster, more reliable queries while keeping your costs low.
In summary, leveraging AWS Glue with Athena ensures that your queries operate on clean, well-structured datasets, leading to improved performance, reduced query errors, and optimized resource usage.
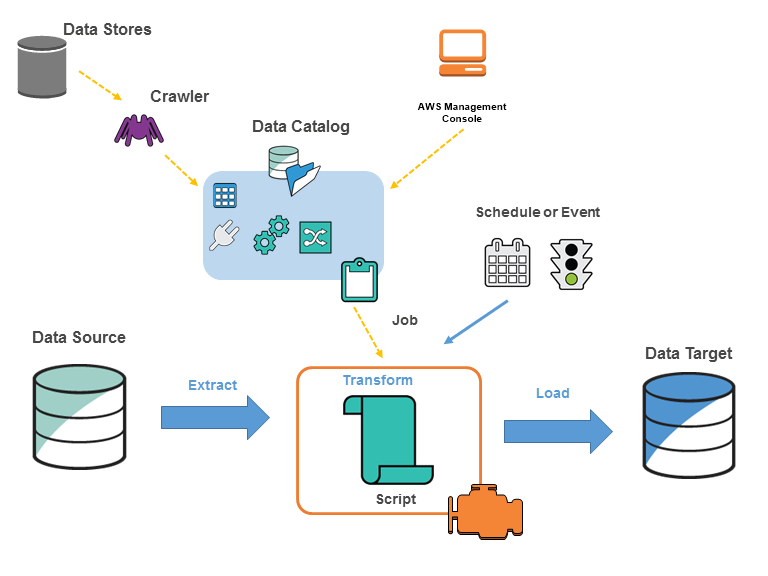
Using Glue, you can also automate ETL (Extract, Transform, Load) processes, converting your raw data into a more efficient, compressed format like Parquet or ORC before loading it into S3. This helps reduce query costs and improves overall performance.
Learn more about AWS Glue here.
6. Monitor and Control Query Costs with CloudWatch and Cost Explorer
Effectively managing query costs in AWS Athena is essential for keeping your cloud budget in check. AWS offers powerful tools like Amazon CloudWatch and AWS Cost Explorer that allow you to gain real-time insights into your query performance and associated costs.
By integrating Amazon CloudWatch with Athena, you can track various performance metrics, such as the number of queries, query run times, and resource consumption. CloudWatch enables you to set up custom CloudWatch Alarms that notify you when query costs exceed predefined thresholds. This proactive monitoring ensures that you can take immediate action when query costs begin to spiral, preventing budget overruns and keeping expenses within your expected limits.
On the other hand, AWS Cost Explorer provides detailed visibility into your Athena usage patterns. It allows you to break down query costs by user, department, or even specific queries. This granular insight helps you identify inefficiencies, such as queries that are running too frequently or consuming unnecessary resources. With Cost Explorer’s filtering options, you can compare different time frames and usage patterns to pinpoint areas for optimization.
Additionally, using Cost Explorer’s forecasting capabilities, you can predict future Athena costs based on historical data, helping you budget more effectively. Combined with CloudWatch’s real-time alerts, this cost analysis gives you full control over your AWS Athena expenses, enabling you to optimize resource allocation, reduce wastage, and ensure that your cloud spend aligns with your financial goals.
TruCost.Cloud: Your AWS FinOps Partner for Continuous Cost Optimization
While these strategies can significantly reduce Athena query costs, ongoing optimization requires continuous monitoring and adjustments. This is where TruCost.Cloud steps in. We offer comprehensive AWS FinOps consulting services, helping you maintain control over your cloud costs while ensuring that your business maximizes the value of its AWS investment.
We specialize in cost allocation, resource tag compliance, and FinOps culture adoption to ensure every dollar you spend on AWS is optimized.
Conclusion: Optimizing Queries for Long-Term Savings
Amazon Athena offers a powerful way to run queries on S3 data, but without the right optimizations, costs can quickly rise. By using compressed data formats like Parquet, partitioning datasets, upgrading to Athena Engine Version 2, and writing efficient SQL queries, you can dramatically reduce AWS query costs.
If you’re ready to take your Athena and AWS cost management to the next level, partner with TruCost.Cloud for expert AWS FinOps solutions. Our team is dedicated to helping you reduce cloud expenses while boosting performance.
Learn more about Amazon Athena here and start optimizing today!
Frequently Asked Questions (FAQs) on Amazon Athena Cost Optimization
1. Why can Amazon Athena queries become expensive?
Athena charges based on the amount of data scanned per query. If your datasets are large and not optimized (e.g., stored in CSV/JSON or without partitioning), queries may scan unnecessary data, leading to higher costs.
2.How can I reduce Athena query costs effectively?
You can lower query costs by using compressed columnar formats (like Parquet/ORC), partitioning your datasets, writing efficient queries, leveraging AWS Glue for schema management, and monitoring costs with CloudWatch and Cost Explorer.
3. What is the benefit of using Parquet or ORC in Athena?
Columnar formats such as Parquet and ORC allow Athena to scan only the specific columns required by a query. This reduces data scanned (and costs) by up to 90% compared to row-based formats like CSV or JSON.
4. How does partitioning data help with Athena cost optimization?
Partitioning organizes datasets into smaller chunks (e.g., by date, region, or department). Queries then scan only the relevant partitions instead of the full dataset, drastically cutting down the scanned data and associated costs.
5. Why should I upgrade to Athena Engine Version 3?
Athena Engine v3 provides faster query execution, dynamic memory optimization, improved JOIN performance, and enhanced cost efficiency. It also supports better workgroup-level cost controls, making it a must for high-volume queries.
6. How can writing efficient SQL queries save money in Athena?
Avoid SELECT * queries since they scan all columns. Instead, select only the needed fields, use LIMIT while testing, and structure joins wisely. These practices reduce the volume of data scanned, lowering costs significantly.
7. What role does AWS Glue play in Athena optimization?
AWS Glue automates data cataloging and schema management, ensuring clean, well-structured datasets. This improves query efficiency, reduces errors, and allows Athena to process only relevant data for faster, cheaper queries.
8. How can I monitor and control Athena costs in real time?
Use Amazon CloudWatch to set query performance and cost alarms, and AWS Cost Explorer to track detailed query expenses by user, team, or workload. Together, they help forecast usage, prevent budget overruns, and enforce cost governance.
9. What’s the best way to test queries without overspending?
Always use the LIMIT clause when testing to scan only a small subset of rows. Once queries are optimized, you can run them on the full dataset to minimize unnecessary scans and costs.
10. How does Athena fit into an AWS FinOps strategy?
Athena becomes cost-efficient when paired with FinOps practices—such as continuous monitoring, cost allocation by team, data partitioning, and regular usage reviews. It ensures cloud spending stays aligned with business goals.








